第05章 集合(後)
5.4 スキャン
スキャン(scan)収集操作は、入力シーケンスの部分リダクションをすべて作成して、新しい出力シーケンスにする。スキャンには以下の2つのバリエションがある。
- 包括的スキャン:n番目の出力値は最初のn個の入力値に対するリダクション
- 排他的スキャン:n番目の出力値は最初のn-1個の入力値に対するリダクション、n番目の出力値が除外
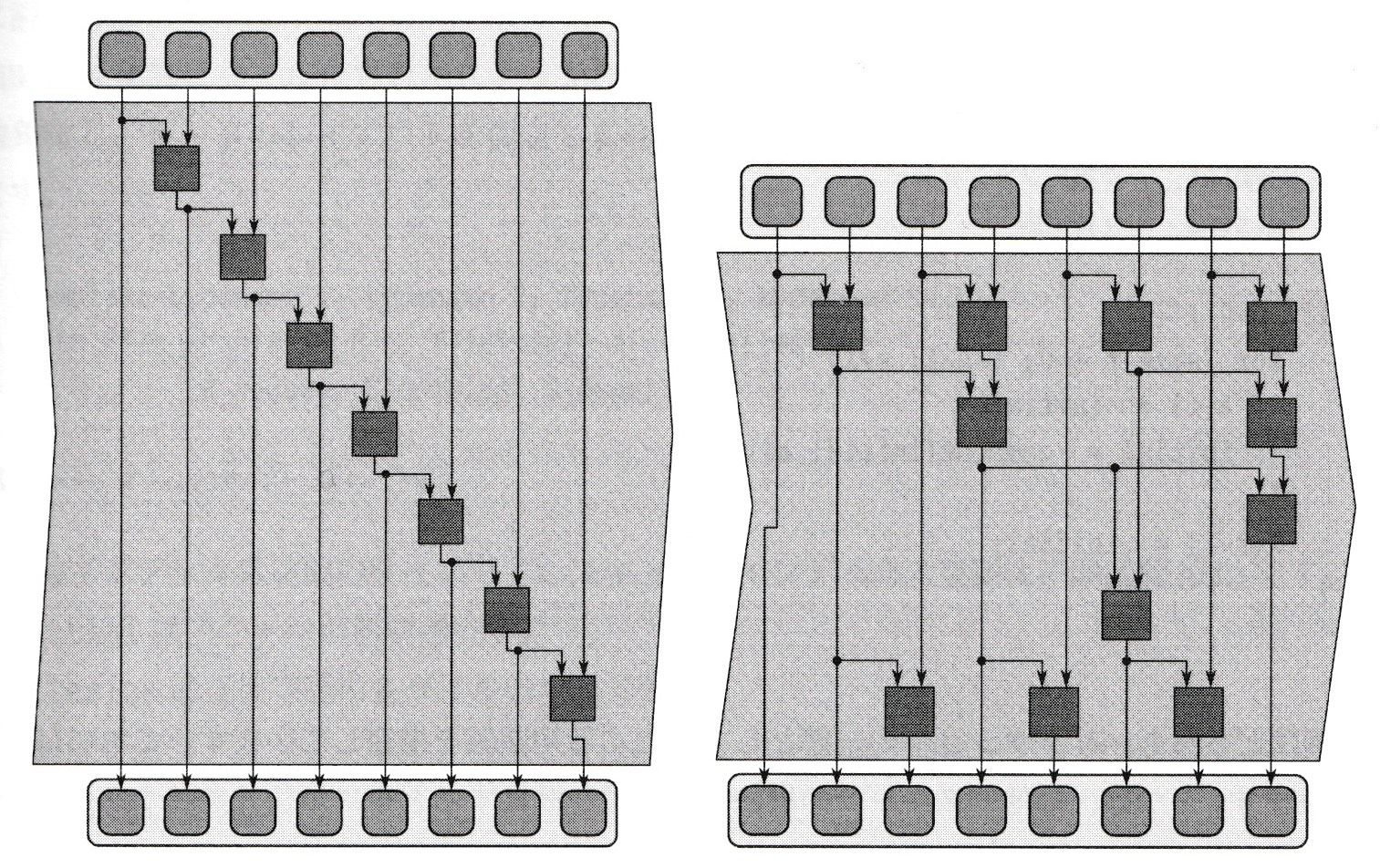 図5-5 スキャンパターンのシリアル実装と並列実装
図5-5 スキャンパターンのシリアル実装と並列実装
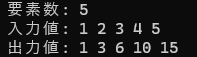
リスト5.14 包括的スキャンのシリアル実装
1
2
3
4
5
6
7
8
9
10
11
12
13 | template<typename T, typename C>
void inclusive_scan(
size_t n, //要素の数
const T a[], //入力コレクション
T A[], //出力コレクション
C combine, //集約ファンクター
T initial //初期値
) {
for (size_t i=0; i<n ; ++i){
initial = combine(initial, a[i]);
A[i] = initial;
}
}
|
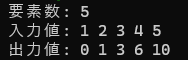
リスト5.15 排他的スキャンのシリアル実装
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 | template<typename T, typename C>
void exclusive_scan(
size_t n, //要素の数
const T a[], //入力コレクション
T A[], //出力コレクション
C combine, //集約ファンクター
T initial //初期値
) {
if( n>0 ){
for (size_t i=0; i<n-1; ++i){
A[i] = initial;
initial = combine(initial, a[i]);
}
A[n-1] = initial;
}
}
|
どちらもリダクションの一部として使用する初期値を指定している。
- 理由1: 排他的スキャンの最初の出力値を演算する時に単位元を持つ必要性を回避するため
- 理由2: タイルされた並列スキャンを記述するためにシリアルスキャンを有用なビルディング・ブロックにするため
スキャンは、ループ伝搬依存があるにもかかわらず並列化することが出来る。レデュースの並列化と似ているため、操作の順序を変更するため集約関数の結合性を活用することが出来る。ただし、冗長な演算コストがかかる。スパンがO(n)からO(lgn)になる代わりに、多くのアルゴリズムではワークがほぼ倍に増える。スキャンを並列化する効率よいアプローチは、フォーク・ジョイン・パターンに基づく手法である。フォーク・ジョイン・パターンについては、第8章で説明する。
5.4.2 TBB
TBBには、包括的または排他的スキャンを行うparallel_scan構造が用意されている。この構造は操作を非決定論的に再結合するため、浮動小数点加算のような非結合操作では結果に決定論性はない。
テンプレートのインターフェイスの引数は再帰的に分割可能な範囲とボディー・オブジェクトの2つ。
| template<typename Range, typename Body>
void parallel_scan( const Range& range, Body& body );
|
範囲はインデックス範囲を指定する。ボディーはレデュース、組み合わせ、スキャン操作を行う方法をCilk Plusインターフェイスと同様の方法で記述する。
5.4.4 OpenMP
OpenMPには組み込み並列スキャンは用意されていないが、OpenMP3.0でサポートされたタスクを使用してフォーク・ジョインCilk Plusコードに似たツリーベースのスキャンを記述することが出来る。以下に説明する3フェーズのスキャンがよく利用される。
- 等しいサイズのタイルに入力を分割し、各タイルを並列にレデュースする。
- リダクション値の排他的スキャンを実行する。このスキャンは常に排他的である。
- 各タイルのスキャンを実行する。各タイルの初期値はフェーズ2の排他的スキャンの結果で、並列スキャンが包括的か排他的かに合わせてこのスキャンを実装すべきである。
3フェーズのスキャンの漸近的実行時間は、Tp=Θ(N/P+P)で、スレッド数がデータ量より十分に小さい場合、N/P項のみ考慮すればよく、スピードアップは線形になる。データ量が固定の場合、N/P+Pの値はP=N のときに最小化される。最大漸近的スピードアップは以下のようになる。
のときに最小化される。最大漸近的スピードアップは以下のようになる。
TpT1=Θ(N/P+PN)=Θ(N/N+NN)=Θ(N)
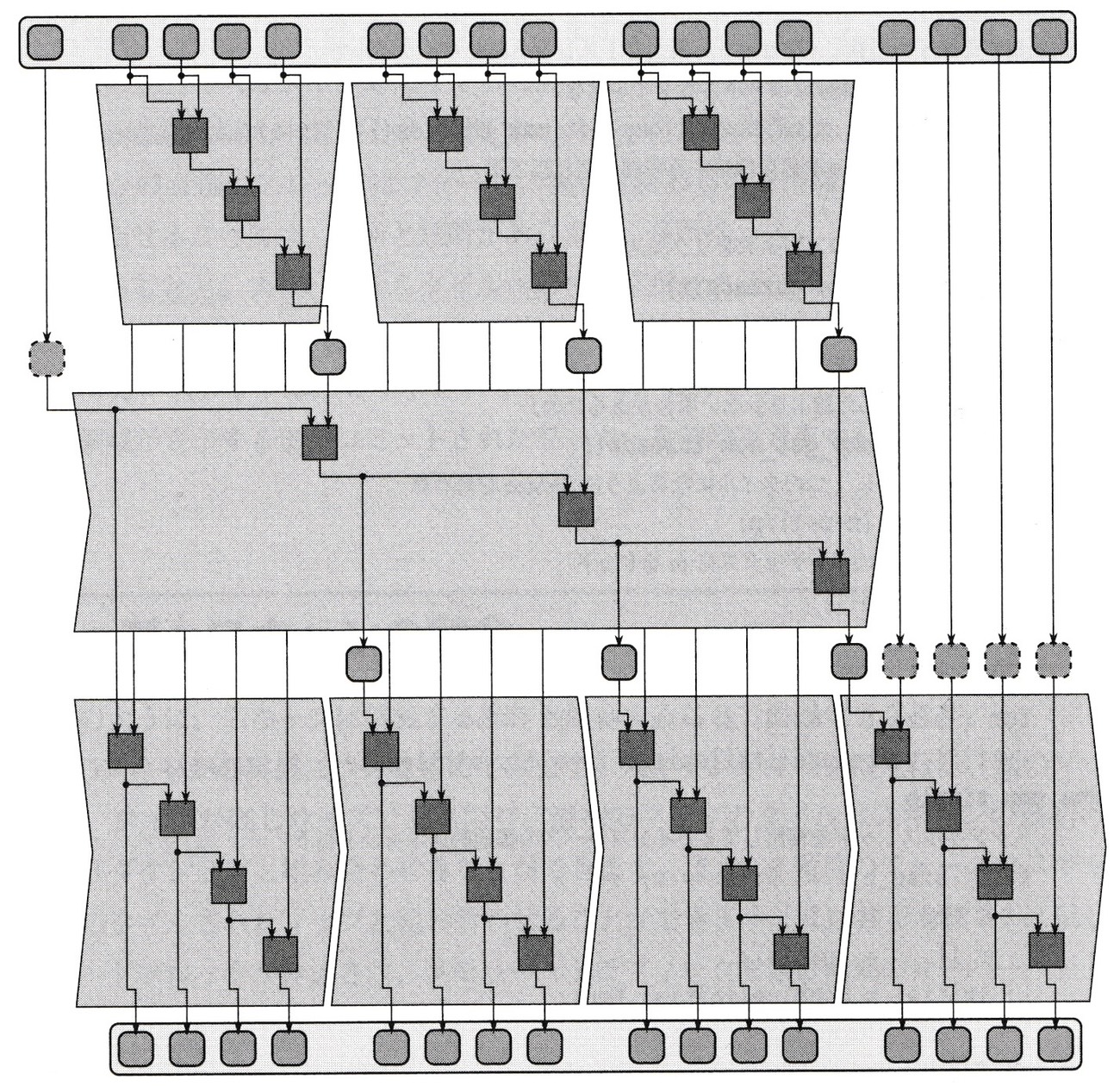 図5-6 初期値を含む、3フェーズの包括的スキャンのタイル実装
図5-6 初期値を含む、3フェーズの包括的スキャンのタイル実装
リスト5.16 OpenMPによる3フェーズのスキャンのタイル実装
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45 | template<typename T, typename R, typename C, typename S>
void openmp_scan(
size_t n,
T initial,
size_t tilesize,
R reduce,
C combine,
S scan
) {
if(n > 0){
//使用するタイルの数にtをセット。最大で1スレッドあたり1タイルで
//リクエストされたtilesizeより小さなタイルはない
size_t t = std::min( size_t(omp_get_max_threads()), (n-1)/tilesize+1 );
//各タイルのリダクション値を保持する空間を割り当てる
temp_space<T> r(t); //リスト8.7参照
//1タイルあたり1つのスレッドをリクエスト
#pragma omp parallel num_threads(t)
{
//実際に許可されたスレッド数を確認
//(リスクエストした数より少ない場合があるため)
size_t p = omp_get_num_threads();
//スレッドごとに1つのタイルになるようにtilesizeを再計算
tilesize = (n+p-1)/p;
//最後のタイルのインデックスにmをセット
size_t m = p-1;
#pragma omp for
//i番目のタイルのリダクションにr[i]をセット
for(size_t i = 0; i <= m; ++i){
r[i] = reduce(i*tilesize, i==m ? n-m*tilesize : tilesize);
}
#pragma omp single
//シングルスレッドを使用してrでインプレースの排他的スキャンを行う
for(size_t i = 0; i <= m; ++i){
T tmp = r[i];
r[i] = initial;
initial = combine(initial,tmp);
}
#pragma omp for
//r[i]を初期値として使用して各タイルをスキャン
for(size_t i = 0; i <= m; ++i){
scan(i*tilesize, i==m ? n-m*tilesize : tilesize, r[i]);
}
}
}
}
|
多くのOpenMPプログラムのように、このコードは利用可能なスレッド数を確認し、スレッドあたり1つのタイルを扱うようにする。並列領域の内部で、コードは取得したスレッド数に基づいてタイルのサイズと数を再計算する。再計算しなかった場合、いくつかのスレッドがほかのスレッドよりも多くのタイルを実行すると、ロード・インバランス(負荷均衡) が発生し、パフォーマンスに影響を及ぼす。
各フェーズは前のフェーズが終了するのを待つが、スレッドはフェーズ間でジョインしない。omp single句が指定された中間フェーズは1つのスレッドのみ実行し、他のm個のスレッドはフェーズの実行が終わるのを待機しているだけ。
5.5 マップとスキャンの融合
レデュースのように、スキャンは隣接する操作と融合することで最適化できる。
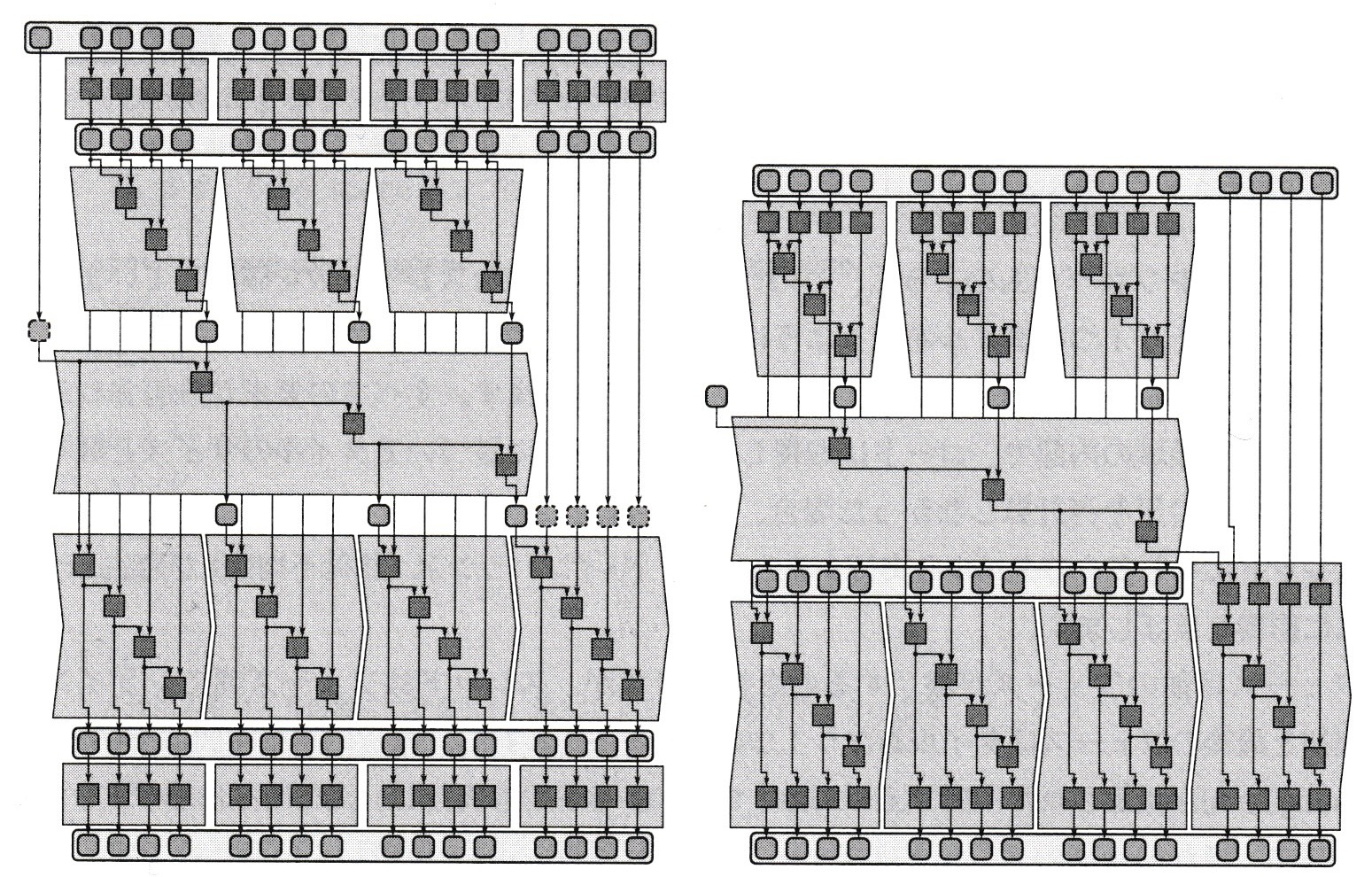 図5-7 融合によるマップと3フェーズスキャンの最適化
図5-7 融合によるマップと3フェーズスキャンの最適化
最初のマップのタイルはスキャンの最初のフェーズのシリアル・リダクションと、3番目のフェーズのスキャンされたタイルは、次のタイルされたマップとそれぞれ組み合わせることが出来る。これにより、より算術的なコードブロックが作成され、メモリー・トラフィックおよび同期のオーバーヘッドが大幅に軽減される。
5.6 積分
スキャンは「並列化できない」アルゴリズムを並列化する要因となることがよくある。
5.6.1 問題の説明
関数fと区間[a,b]に対し、[a.b]の任意の部分区間でfの定積分を迅速に計算できるテーブルをあらかじめ計算する。
Δx=(b−a)/(n−1)であるとする。テーブルはfのサンプルの累積和で、スケールはΔx。
tablei=Δx∑0if(a+iΔx)
区間[c,d]のfの積分は次のように推定できる。
∫cdf(x)dx≈interp(d)−interp(c)
interp(x)はテーブルの線形補間を示す。
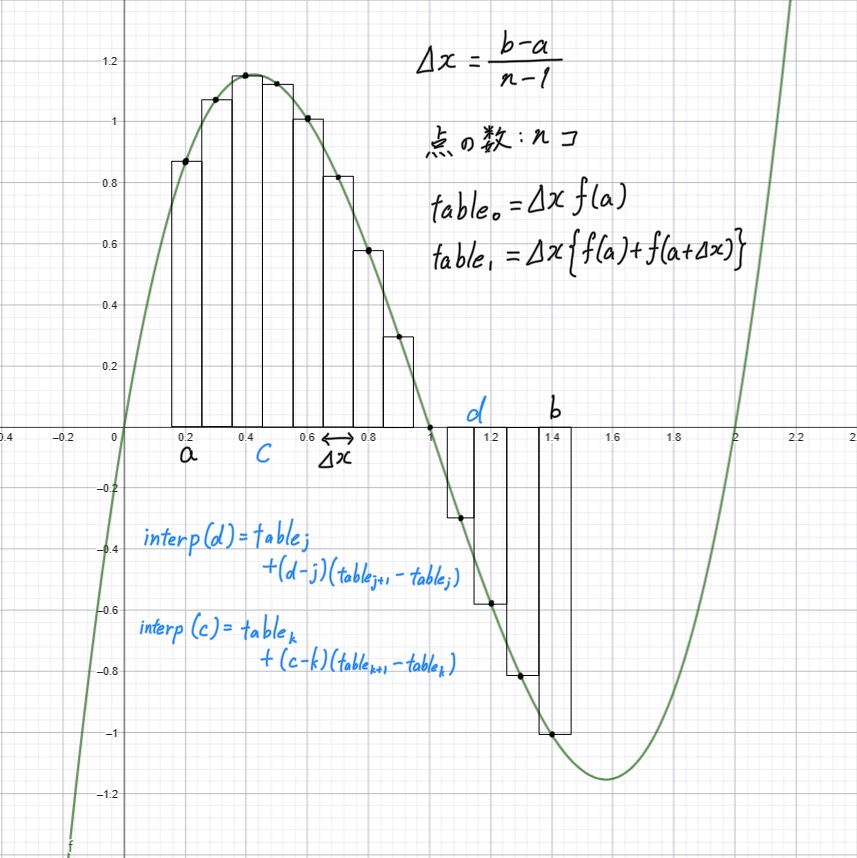 図5-8 積分法
図5-8 積分法
5.6.2 シリアル実装
リスト5.17は、サンプリングおよび和計算のシリアル実装を示す。ループ反復がそれぞれ前の反復に依存するためループ伝搬依存がある。
リスト5.17 シリアル積分テーブルの準備
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19 | template<typename X, typename Y, typename F>
void serial_prepare_integral_table(
X a, //サンプリングの開始位置
X b, //サンプリングの終了位置
size_t n, //処理するサンプルの数
Y table[], //テーブルサンプルのデスティネーション
F f //関数パラメーター
) {
//空のリクエストを制御
if(n==0) return;
//サンプル間隔を計算
const X dx = (b-a)/X(n-1);
//サンプルポイントのスケールされた累積和をtable[0:n]に格納
Y sum = Y(0);
for(size_t i = 0; i < n; ++i){
sum += f(a+dx*i); //f: XをYにマップ
table[i] = sum * dx;
}
}
|
リスト5.20は、2つのサンプルから定積分を求める方法を示す。配列を線形補間してルックアップするヘルパー関数serial_sampleを定義する。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35 | template<typename Y, typename X>
Y serial_sample(
size_t n,
Y table[],
X x
) {
//サンプル位置の整数部を計算
X i = floor(x);
//iとi+1のサンプルをルックアップ
//境界外のインデックスについては左に0右にtable[n-1]を使用
Y y0 = i < X(0) ? Y(0)
: table[i < X(n) ? size_t(i) : n-1];
Y y1 = i+1 < X(0) ? Y(0)
: table[i+1 < X(n) ? size_t(i+1) : n-1];
//サンプル間をリニアに補間
return y0 + (y1-y0)*(x-i);
}
template <typename X, typename Y>
Y serial_integrate(
size_t n, //テーブルのサンプル数
Y table[], //サンプルを累積
X a, //関数ドメインの下限
X b, //関数ドメインの上限
X x0, //積分の下限
X x1 //積分の上限
) {
//x0とx1をテーブル・インデックスに変換するためのスケールを計算
X scale = X(n-1)/(b-a);
//不定積分の補間された値をルックアップ
Y y0 = serial_sample(n, table, scale*(x0-a));
Y y1 = serial_sample(n, table, scale*(x1-a));
//積分を計算
return y1 - y0;
}
|
5.6.4 OpenMP
リスト5.21は、積分テーブルを準備するOpenMPコードを示す。関数の最初のマッピングは、タイル・リダクションを行うファンクターに融合される。スキャンの最後のスケーリングは、タイルスキャンを行うファンクターに融合される。
リスト5.21 OpenMPによる積分テーブルの準備
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32 | template<typename X, typename Y, typename F>
void omp_serial_prepare_integral_table(
X a, //サンプリングの開始位置
X b, //サンプリングの終了位置
size_t n, //処理するサンプルの数
Y table[], //テーブルサンプルのデスティネーション
F f //X→Yにマップする関数
) {
//空のリクエストを制御
if(n==0) return;
//サンプル間隔を計算
const X dx (b-a)/X(n-1);
//並列スキャンを実行
openmp_scan(
n, Y(0),
1024, //タイルサイズ
[=, &table] (size_t i, size_t m) -> Y {
Y sum = Y(0);
for( ; m>0; --m, ++i)
sum += (table[i] = f(a + dx*i));
return sum;
},
std::plus<Y>(),
[=, &table](size_t i, size_t m, Y initial) {
//サンプルポイントの累積和をtable[i:m]に格納
for( ; m>0; --m, ++i){
initial += table[i];
table[i] = initial*dx;
}
}
);
}
|
付け足したメイン関数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18 | int main() {
const size_t n = 10;
double table[n];
//f(x) = x^2
auto f = [](double x){
return 3*x*x;
};
omp_serial_prepare_integral_table(0.0, 1.0, n, table, f);
printf("積分テーブル:\n");
for(size_t i = 0; i < n; ++i){
printf("table[%zu] : %f\n", i, table[i]);
}
return 0;
}
|
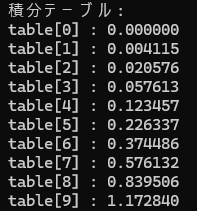
nを1000にした場合(一部抜粋)
table[0] = 0.000000
table[100] = 0.001018
table[200] = 0.008084
table[300] = 0.027217
table[400] = 0.064433
table[500] = 0.125752
table[600] = 0.217191
table[700] = 0.344769
table[800] = 0.514502
table[900] = 0.732410
table[999] = 1.001502
∫013x2dx=[x3]01=1
配列表記をループ構造に置換することも出来るが、OpenMPの配列表記は、スレッド並列とベクトル並列を活用する効果的な方法であるため、必須ではない。また、この変更を行うにはOpenMPの並列化モデルをサポートするコンパイラーが必要になる。
5.6.5 TBB
TBBのparallel_scanテンプレートは、実際に並列処理が発生しない場合、各要素で集約関数を2回呼び出さないよう最適化されている。この最適化が行われるとマップとスキャンのレデュース部分を融合されないため、積分ではタイルの両方のパスで各サンプルポイントを計算しなければならない。サンプルの計算に時間がかかる場合、余分な計算を回避するため、あらかじめサンプルを計算してスキャンを呼び出す前にテーブルに格納する。
リスト5.22にコードを示す。TBB実装では、単一のテンプレートoperator()でタイルレデュースとタイルスキャンの両方の処理を行う。13行目の式tag.is_final_scan()の値は、以下の2つを区別する。
真
Bodyの状態は、サブ範囲rに先行するループの全ての反復と同じ。このケースでは、operator()はサブ範囲をシリアルスキャンして、Bodyを現在のサブ範囲を超えて継続するために適した状態にする。
偽
Bodyの状態は、サブ範囲rに先行する全ての反復ではなく、先行する0個以上の連続する反復を表す。このケースでは、operator()は現在のサブ範囲のリダクションが含まれるように状態を更新する。
リスト5.22 TBBによる積分テーブルの準備
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45 | template<typename X, typename Y, typename F>
struct Body{
const X a, dx;
Y* const table;
F f;
//累積和
Y sum;
//タイルのリダクションまたはスキャン
template<typename Tag>
void operator() (tbb::blocked_range<size_t> r, Tag tag){
for(size_t i = r.begin(); i != r.end(); ++i){
sum += f(a + dx*i);
if(tag.is_final_scan())
table[i] = sum*dx;
}
}
//bodyを初期化
Body(X a_, X dx_, Y* table_, F f_)
: a(a_), dx(dx_), table(table_), f(f_), sum(0) {}
//ルックアヘッド・リダクションのbodyを作成
Body( Body& body, tbb::split)
: a(body.a), dx(body.dx), table(body.table), f(body.f), sum(0) {}
//2つの連続する範囲のbodyをマージ
void reverse_join(Body& body) {sum = body.sum + sum; }
//最後のタイルの最後のbodyの状態を*thisに代入
void assign( Body& body ) {sum = body.sum;}
};
template<typename X, typename Y, typename F>
void tbb_prepare_integral_table(
X a, //サンプリングの開始位置
X b, //サンプリングの終了位置
size_t n, //処理するサンプルの数
Y table[], //テーブルサンプルのデスティネーション
F f //X→Yにマップする関数
) {
//空のリクエストを制御
if(n==0) return;
//サンプル間隔を計算
const X dx = (b-a)/(n-1);
//スキャンのbodyを初期化
Body<X, Y, F> body(a, dx, table, f);
//スキャンを実行
tbb::parallel_scan( tbb::blocked_range<size_t>(0, n), body);
}
|
2番目のケースは、スレッドがparallel_scanのワークを実際にスチールした場合にのみ発生する。
メソッドreverse_joinは2つの隣接するサブ範囲の状態をマージする。左のサブ範囲は、シリアルスキャン後の一部または完全な状態のいずれかになる。
メソッドassignは最後に使用され、オリジナルのBody引数を、最後の反復後のBodyの状態が含まれるtbb::parallel_scanに更新する。
5.7 まとめ
この章ではレデュースとスキャンの2つの集合パターンの概要と実装におけるさまざまなオプションの説明をした。OpenMPによる3フェーズのスキャンはこの後のフォーク・ジョインの実装よりはスケーラブルではない。レデュースとスキャンはマップとともによく使用され、隣接するマップと実装(の一部)を融合して、あるいはマップとレデュース/スキャンの順序を逆にして、最適化することが出来る。